Recent advances in text-to-video generation have harnessed the power of diffusion models to
create visually compelling content conditioned on text prompts. However, they usually encounter
high computational costs and often struggle to produce videos with coherent physical motions. To
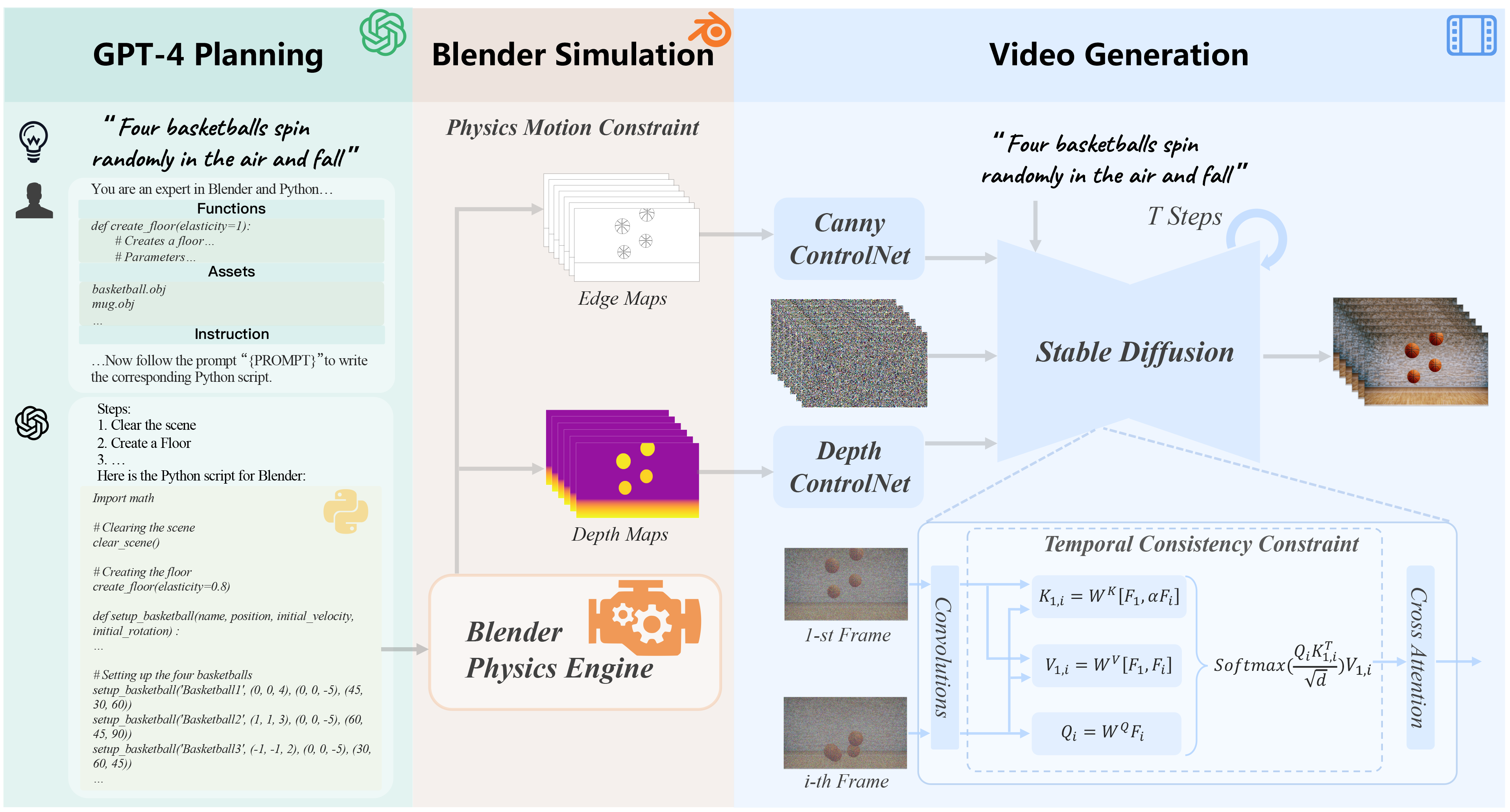
tackle these issues, we propose GPT4Motion, a training-free framework that leverages the
planning capability of large language models such as GPT, the physical simulation strength of
Blender, and the excellent image generation ability of text-to-image diffusion models to enhance
the quality of video synthesis. Specifically, GPT4Motion employs GPT-4 to generate a Blender
script based on a user textual prompt, which commands Blender's built-in physics engine to craft
fundamental scene components that encapsulate coherent physical motions across frames. Then
these components are inputted into Stable Diffusion to generate a video aligned with the textual
prompt.
Experimental results on three basic physical motion scenarios, including rigid object drop and
collision, cloth draping and swinging, and liquid flow, demonstrate that GPT4Motion can generate
high-quality videos efficiently in maintaining motion coherency and entity consistency.
GPT4Motion offers new insights in text-to-video research, enhancing its quality and broadening
its horizon for further explorations.